En esta entrada de «Qué pasa si» vamos a realizar una terrible locura que ningún administrador de sistemas desea tener en sus sistemas. Tener máquinas virtuales con discos en thin-provisioning es muy bonito y tiene muchos beneficios cuando está controlado. ¿Y si no está controlado, es decir, estás haciendo un overprovisioning sin tener un datastore con capacidad suficiente para que las máquinas crezcan?
¿Sabéis lo que toca no? Efectivamente… ¡hora de romper cosas en un laboratorio controlado!
Entorno de laboratorio
Para esta prueba se ha levantado dos hypervisores ESXi en versión «7.0.3, 18644231» y vCenter Server Appliance en versión «7.0.3, 18778458«. Como sistema base tenemos Ubuntu 20.04 con el servicio de iSCSI para dar un datastore compartido entre los dos hypervisores respaldado por un disco NVMe Samsung 970.
Las pruebas se realizarán sobre el primer hypervisor dejando el segundo de forma exclusiva para vCenter Server.
Se han instalado las siguientes máquinas virtuales:
- Windows XP con 10GB de disco en modo thin-provisioning formateado en FAT32
- Windows server 2019 con 70GB de disco en modo «Puesta a cero lenta con aprovisionamiento grueso» formateado en NTFS
- CentOS 7 con 20GB de disco en modo thin-provisioning formateado en XFS
- Ubuntu 20.04 con 15GB de disco en modo «Puesta a cero lenta con aprovisionamiento grueso» formateado en EXT-4

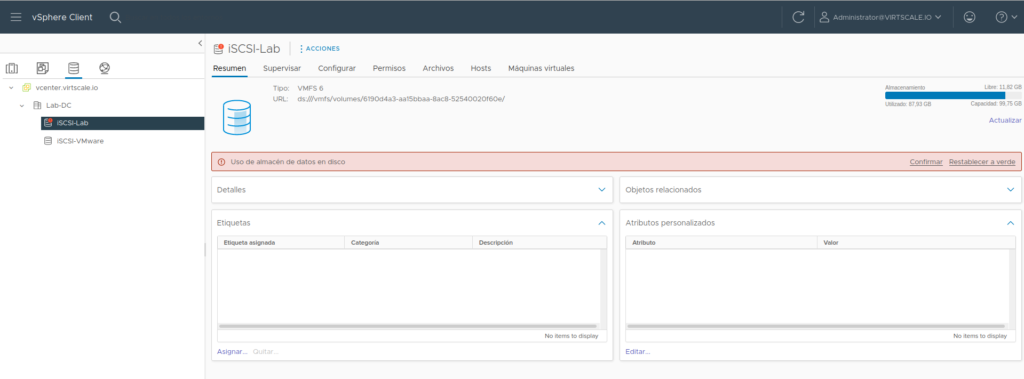
Recordad que esto es un laboratorio y que nos podemos permitir realizar este tipo de locuras. En producción nunca dejéis vuestros datastores tan agobiados.


Anyway… ¡Hora de romper cosas!
Tengo espacio de sobra, voy a bajarme internet entero.
En esta ocasión va a ser muy fácil probar que ocurre. El plan, es el siguiente:
- Arrancar todas las máquinas virtuales.
- Comprobar que el datastore tiene más de 10GB de espacio libre real
- Lanzar con el comando ‘dd‘ escrituras infinitas tanto en CentOS como en Ubuntu para llenar el datastore.
- En Windows XP hemos creado un fichero dummy.txt de 1MB y lo único que haremos es ir copiando y pegando el fichero para generar escrituras en disco.
- Ir a la cocina a por palomitas para ver como se rompe todo. Diversión ante todo.
El comando que se va a lanzar en las dos máquinas es el siguiente:
dd if=/dev/urandom of=dummy bs=4M oflag=directLanzamos el comando, empezamos a duplicar el fichero en Windows XP y tras unos segundos… ¡Oh no! tenemos la máquina de CentOS y la de Windows XP detenidas



Si vamos a la información de la máquina en vCenter vemos que nos muestra el siguiente mensaje:
No hay más espacio para el disco virtual ‘CentOS 7.vmdk’. Es posible que pueda continuar esta sesión si libera espacio de disco en el volumen correspondiente y hace clic en Reintentar. Haga clic en Cancelar para finalizar esta sesión.
No hay más espacio para el disco virtual ‘Windows XP.vmdk’. Es posible que pueda continuar esta sesión si libera espacio de disco en el volumen correspondiente y hace clic en Reintentar. Haga clic en Cancelar para finalizar esta sesión.
Las máquinas de Ubuntu 20.04 y Windows Server 2019 siguen funcionando perfectamente. ¡Espera un momento, si no hay espacio en el datastore!
¿Qué está pasando aquí?
En la sección de «Entorno de laboratorio» explico qué tipo de disco tiene cada máquina virtual y las dos que siguen funcionando con normalidad son las máquinas que tienen el tipo de disco «Aprovisionamiento grueso» por lo cual, no debe solicitar espacio al datastore ya que ese espacio está en uso/asignado desde que se crea la máquina.
Si, muy bonito todo, pero… ¿qué ha pasado con las máquinas que estaban en thin-provisioning?
Respuesta rápida y sencilla, tal y como hemos dicho antes, están pausadas y a la espera de una respuesta del usuario para poder reanudar la máquina.
VMware protege las máquinas virtuales que están en modo thin-provisioning, detectando cuando realiza escrituras en disco y si el datastore donde está entra en una condición de error (como por ejemplo, que se quede sin un espacio seguro para funcionar) automáticamente va pausando las máquinas.
Esta parada no la realiza sobre todas las máquinas a la vez si no que realiza esta operación cuando la maquina realiza escrituras en disco. Si la máquina está en modo thin-provisioning y no realiza escrituras seguirá funcionando.
Arreglando el desastre
Ahora mismo no podemos darle a continuar a las dos máquinas que tenemos detenidas ya que nuestro datastore continua lleno, por lo cual nos tocaría ampliar nuestro datastore para darle más espacio y que puedan continuar.
Esto es una SAN de gama empresarial es bastante sencillo, entras a su panel web bonito, le das a expandir y le das espacio. Yo, como soy así de chulo, tengo que ver como ampliar el espacio de mi iSCSI en mi Ubuntu físico, ni idea de como se hace, lo mismo lo rompo todo.

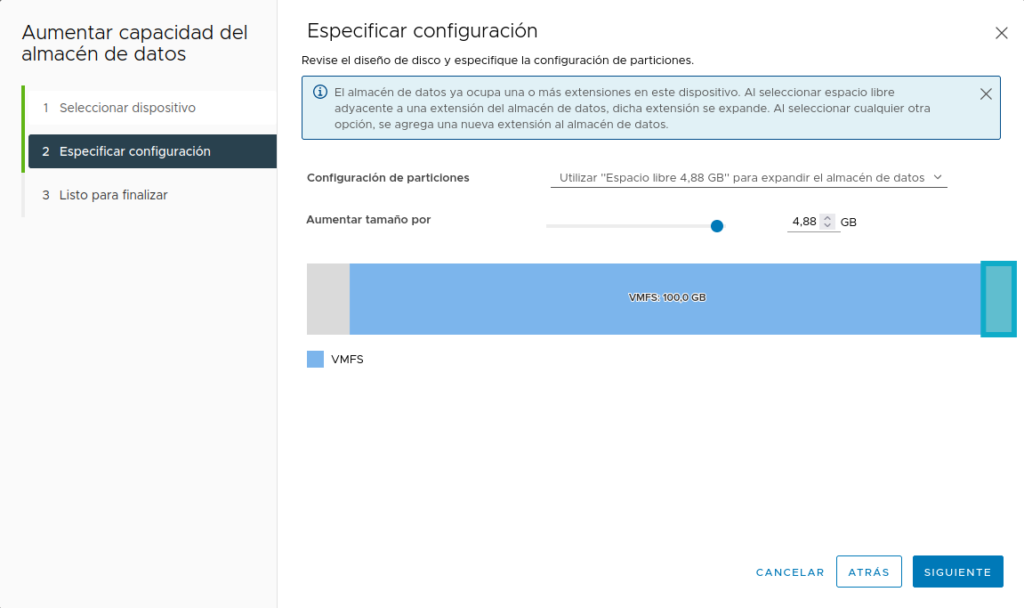
Tras añadir 10GB de disco a nuestro datastore (fue sencillo con dd en modo append), vamos a responder la pregunta en la máquina virtual:

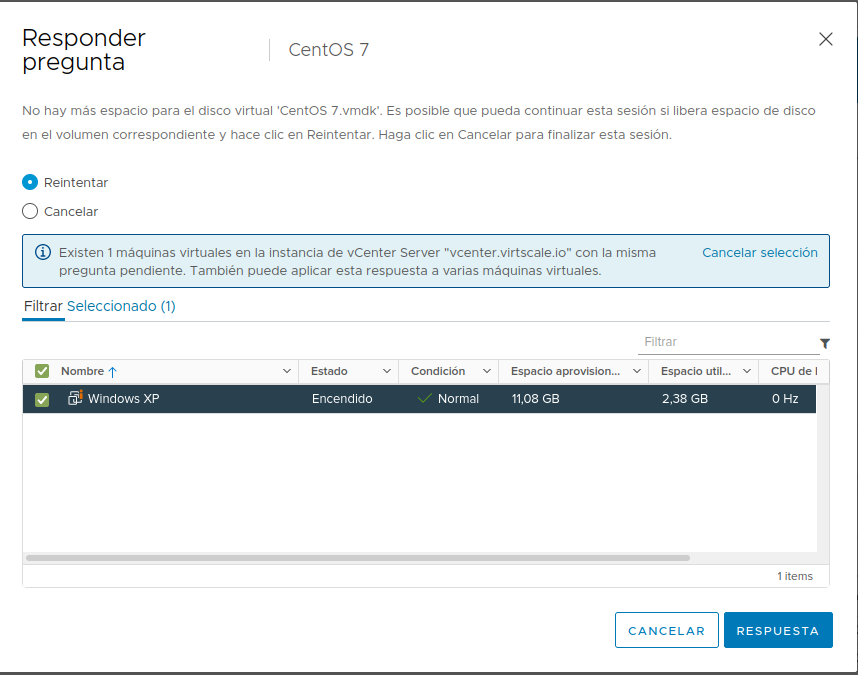
Y… ¡Perfecto! Las máquinas han continuado como si no hubiese pasado absolutamente nada. Tras realizar comprobaciones de disco con fsck en CentOS como con chkdsk en Windows XP no se ha detectado ninguna corrupción de datos.
Final
Tal y como hemos visto, VMware te protege frente la condición de espacio bajo o llenado completo poniedo en pausa las máquinas virtuales que están intentando escribir en disco. Para más información: https://kb.vmware.com/s/article/1003412
Como recomendación personal, insisto en poner siempre poner algún tipo de monitorización con alertas, como Nagios o Zabbix, que te avise cuando vuestros datastore se estén llenando para que nunca se de este condición ya que.. «más vale gigas libres que noche despierto recuperando máquinas»

